Motivation
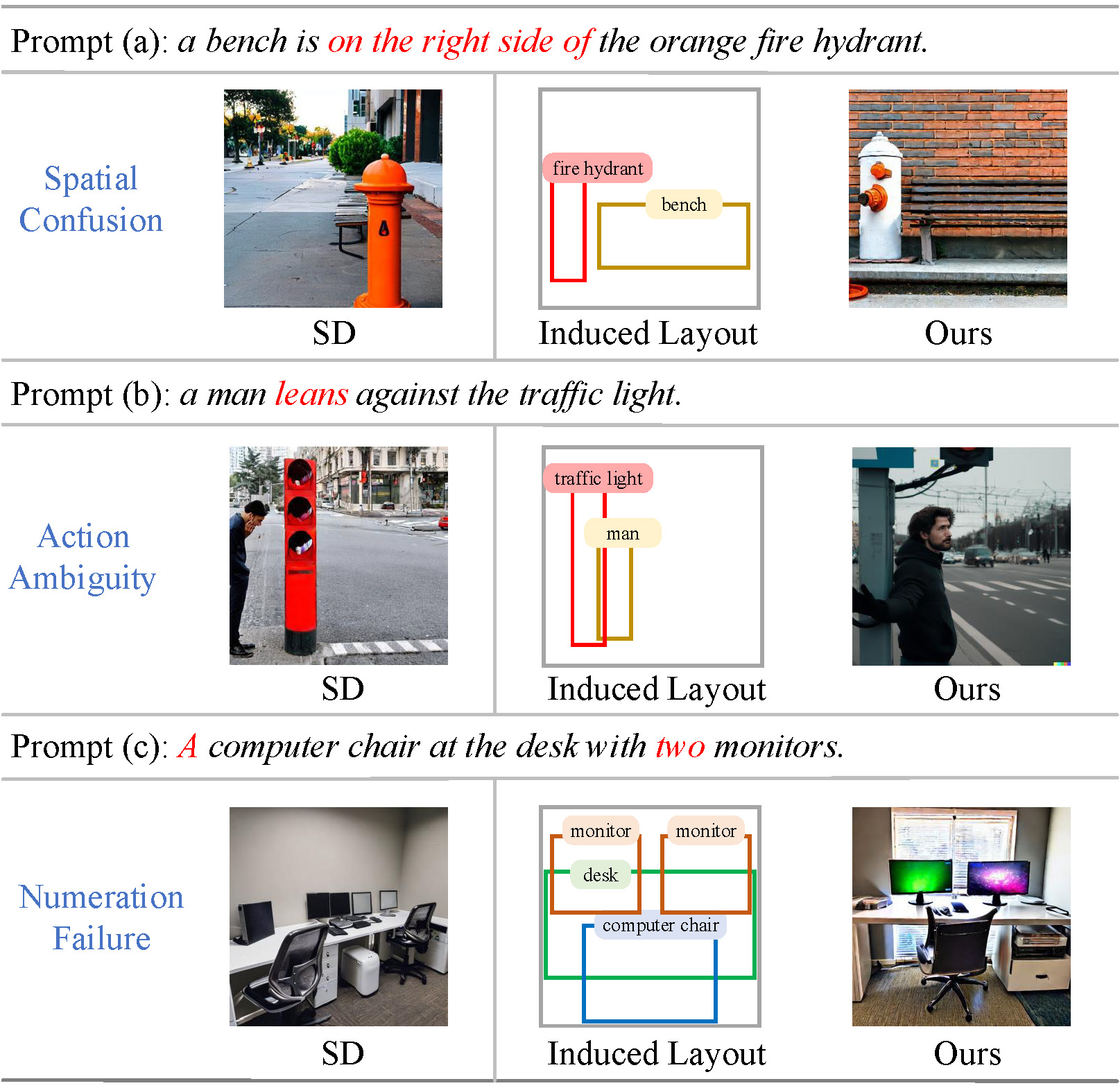
Despite the satisfactory performance achieved by recent SD-based models, synthesizing high-faithful images in complex scenes is still challenging, such as problematic spatial relation understanding and numeration failure, as shown in the following figure. However, to achieve high-faithfulness image synthesis, the existing models suffer from the following challenges:
- Layout Planning requires abstract spatial imagination and analysis capabilities. The limited annotated layout data and intrinsic inductive bias make it difficult for existing diffusion methods to accurately and aesthetically generate layouts. Although notable efforts have been dedicated to synthesizing complex scenes by manually providing guidance information, these strategies suffer from weak flexibility and low efficiency since they heavily rely on extra labor-intensive guidance.
- Relation Modeling, e.g., the high-level spatial and semantic relations, plays a pivotal role in understanding, imagining, and depicting complex scenes for T2I models, but it is still under-explored owing to the complex and ever-changing environments in real life.
Framework
In Figure 2, we illustrate the overall architecture of the proposed layout-guided diffusion model, consisting of two modules:
- Text-to-layout induction module infers a coarse-grained layout via an LLM conditioned the given textual prompt.
- Layout-guided image generation module synthesizes the final image based on the prompt and the generated layout, .
Generated Images
Examples: Spatial, Semantic
Results on the Spatial, and Semantic inputs. The ground-truth (GT) image, the ground-truth layout with the generated image (GT*), the layout generated from LayoutDM, and our results for each prompt are shown from left to right.

Examples: Numerical, Mixed, Null
Results on the Numerical, Mixed, and Null inputs.

Related Links
You may refer to previous works such as GLIGEN, Stable Diffusion, and GPT3.5, which serve as foundational frameworks for our LayoutLLM-T2I framework and code repository.